Datalake comparaison - 9 Cloudspanner
Dans ce chapitre nous allons nous consacrer à la solution Cloudspanner, une solution managée
sur la plateforme cloud de Google GCP, cette solution a été développée par Google et est de ce fait
une exclusivité GCP. Cette solution a été développée par Google pour ses propres besoins de
gestion de grosses bases de données, elle est utilisée chez Google depuis plus de 4 ans sur des
applications critiques. Google passe régulièrement le reste de ses applications critiques sur cette
technologie (Gmail, adsense,adwords...)
Si vous voyez des erreurs commises dans ce comparatif veuillez nous adresser un mail à
contact@domwee.com nous nous efforcerons de corriger le plus rapidement possible.
- Architecture simplifiée
L’architecture utilise des nœuds et des réplications, les tables sont réparties dans ces nœuds et les réplications sont utilisées pour faire des accès en lecture et de la redondance d’information pour éviter toute perte de données.
Comme les données d’une même table sont réparties dans des partitions sur plusieurs nœuds Google a opté pour la mise en place d’un service en amont qui permet de retrouver rapidement les données recherchées. Le stockage des données se fait en ligne et non en colonne. Comment fonctionne les partitions et les nœuds et les les réplications? Seront numérotées de 0 à 8 les 9 partitions de données. Les partitions principales sur lesquelles sont faites les opérations d’écritures sont en bleues foncées et les réplicas sont en bleus plus clair. Les nœuds sont en gris et n’ont pas de numéro. L’instance utilise 3 zones différentes vous trouverez ci dessous comment Cloudspanner organisera les données :

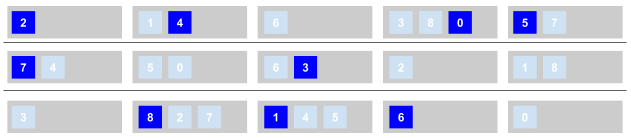
Nous remarquons qu’il n’y a qu’une seule partition principale par nœud et que les répartitions des partitions secondaires se fait aléatoirement.
La répartition des données se fait selon la clé primaire de chaque table. Le choix de cette clé primaire est donc essentielle pour le bon fonctionnement de la solution. C’est une base de données SQL et elle permet de faire des jointures entre les tables. Afin de faciliter ces jointures il est possible de créer des tables liées et la clé de la table liée doit reprendre la clé primaire de la table principale pour que les données jointes soient stockées au même endroit. La solution permet à tout moment d’agrandir le nombre de nœuds. Le nombre de nœuds ne grandit pas de manière automatique. Il n’y a pas d’autoscaling. Cette architecture est managée par Google et la création de partition et leurs répartitions est automatique.
- BigData
L’architecture est prévue pour gérer du BigData les répartitions de données sont bien pensées et l’utilisation de réplicas permet de faire du failover, de la sauvegarde de données et une répartition de charge sur des opérations non bloquantes comme de la lecture. Le seul reproche c’est qu’il faut beaucoup de serveurs et que cette base de données coûte chère. Si vous avez assez de nœuds et que les indexs sont bien choisis il est possible d’insérer des centaines de milliers de lignes à la seconde. Oui c’est extrême et peu d’entreprises ont ces besoins mais Google qui gère des milliards d’utilisateurs a besoin de ce genre de puissance. - Datawarehouse
Si vous maîtrisez bien le système de tables liées c’est une solution qui aura des bonnes performances en requêtes avec des jointures. La possibilité de faire des updates et des deletes et l’utilisation du SQL standard complète la palette des besoins d’un datawarehouse. Les seuls petits bémols le prix et nous n’avons vu qu’un driver JDBC et pas de driver ODBC. - Reporting
Cet outil ferait du bon travail pour faire du reporting. La structure proposée par Google permet des requêtes sub seconde. La montée en charge avec les réplicas de données ne serait pas un problème et permet même de parer à une défaillance temporaire d’un des nœuds (surcharge de travail, problème matériel). Le seul point noir est l’absence de driver ODBC qui limite le choix des outils de restitution des données. - Datalake
Cet outil ne fait pas un très bon datalake. Premièrement seules les données structurées sont acceptées par cette base de données qui aura certes de très bonnes performances mais son prix, l’absence d’autoscaling et sa complexité de mise en place (choix d’index et table entrelacées ou liées) empêchent de prétendre à un très bon outil de datalake. - Base de données Applicative
C’est une excellente base de données applicatives pour les outils critiques. Tout y est : performance, sécurité avec failover et réplication en live, performances extraordinaires, SQL standard. Cette base de données a été construite pour cela, pour gérer les applications critiques de Google et à la vue des spécifications nous pouvons dire que Google a réussi son coup. - Utilisateurs
Il existe une interface web pour faire les requêtes, les utilisateurs de requêtes n’auront que cela à utiliser ou des rapports. Ils n’ont besoin que de performances et de simplicité et c’est ce que propose Cloudspanner. Pour les datascientists et dataengineer la donne est plus compliquée avec le choix des index et les tables entrelacées. - Fonctionnalités additionnelles
Ici ne seront traitées que les fonctionnalités natives présentent dans le moteur de la base de données, sinon ce tableau n’aura aucun sens puisqu’avec du développement ou des addons on pourrait tout faire avec n’importe quelle base de données.
- Géographiques :
- Graphes :
- IP :
- Window :
- ML : - Administrateur
C’est une solution managée mais les administrateurs devront surveiller l’utilisation CPU pour ajuster le nombre de nœuds. - Experts quand pourquoi
Cette solution nécessitent des experts pour qu’elle tourne de manière optimale. Une instance mal configurée tournera comme une base de données SQL classique et n'apportera aucun gain notable. - Droits et sécurité
Les droits sont liés à des comptes Google, seules les personnes ayant des comptes Google (Gmail.com ou G Suite) peuvent utiliser cette solution. Les droits sont complets mais ils ne descendent pas très loin ils s’arrêtent au niveau de la base de données. Cette solution est compatible SAML et permet aussi de se connecter à un active directory. - Logs et alertes
Les logs sont disponibles dans l’outil de requêtage et sont déjà bien fournies. Mais en plus ils sont stockés dans stackDriver un outil de centralisation de logs. Google propose un système d’alertes personnalisées ce qui est intéressant pour surveiller l’utilisation du CPU. - Coût et gestion
Les coûts sont élevés mais sont fixes, puisque c’est un coût de stockage et un coût au nombre de nœuds. Il n’y a pas de frais de licence si ce n’est les comptes Google pour accéder au service. - Fin d’utilisation
Il est possible à tout moment d’exporter les données d’une instance dans fichiers Avro sur cloud storage. - Documentation et API
La documentation est assez bien faite mais n’est pas la plus claire que nous ayons vue, en revanche au niveau API comme tout le temps avec Google c’est du très haut niveau.
Les notes vont de 0 à 5 (5 étant la meilleure)
1.1
B
I
G
D
A
T
A
|
1.2
DWH
|
1.3
R
E
P
O
R
T
|
1.4
D
A
T
A
L
A
K
|
1.5
A
P
P
S
|
2
U
T
I
L
I
S
A
|
3
F
O
N
C
T
+
|
4
A
D
M
|
5
E
X
P
E
R
T
|
6
D
R
O
I
T
S
|
7
L
O
G
S
|
8
C
O
U
T
|
9
F
I
N
|
10
D
O
C
| |
CloudSpanner
|
4,5
|
4
|
4
|
2
|
3,5
|
3
|
1
|
3,5
|
5
|
2
|
2,5
|
4
|
Conclusion : Cette base de données est vraiment excellente pour une application critique. Son
architecture et ses innovations méritent vraiment que plus de personnes s’intéressent à cette
solution.
Plan :
1 introduction
Plan :
1 introduction



Commentaires
Enregistrer un commentaire