Data loss prevention API
Les entreprises traitent de plus en plus leur données automatiquement. Plusieurs profils peuvent
être amenés à “jouer” avec leurs données : data scientists internes, data scientists externes ou
entreprises spécialisées dans ce domaine. Par faute de temps ou par manque d’outil les données
fournies ne sont pas toujours pré traitées et sont souvent envoyées telles quelles, or cela a deux
inconvénients : le premier (que tout le monde avait trouvé) transmettre des informations importantes
inutiles et donc augmenter le risque de fuite d’information, Le deuxième c’est qu’une donnée trop
riche nuit à son traitement. Je donne un exemple pour un ordinateur un numéro de téléphone est
une suite de 4 numéros et s’ils ne sont pas contextualisé il prendra cela pour 4 numéros de 2
chiffres. Dans certains cas il est préférable de remplacer ces 4 séries de chiffres par un libellé
comme NumTéléphone pour faire comprendre à l’algorithme que c’est l’information de la présence
de numéros de téléphone qui prime et pas la présence du chiffre 43 qui est important.
1.Anonymisation, pseudonymisation et contextualisation des données
Il existe différents niveaux de transformation des informations sensibles. Dans certains cas on
souhaite anonymiser les données c’est à dire remplacer toute information personnelle par un
algorithme qui ne permet pas de revenir en arrière. Dans un autre cas va utiliser la
pseudonymisation, c’est à dire rendre une donnée non reconnaissable pour un traitement tout en
gardant ces caractéristiques. En général il s’agit juste d’appliquer un cryptage réversible sur les
données tout en conservant le même type de données en sortie : des dates sont remplacées par
d’autres dates des libellés par d’autres libellés etc. On peut encore vouloir masquer ou faire
disparaître des informations sensibles. Tous ces mécanismes passent par la même étape de base :
identifier ces données sensibles et c’est ce que nous allons voir dans cet article.
2.API data loss prevention de Google

Il existe une API Data loss prevention, souvent appelé dlp dans Google qui permet d'identifier un
bon nombre de données considérées comme sensibles. Cette API a été développée avant tout pour
les besoins GDPR, elle saura identifier les numéros de carte bancaires, les numéros de passeport,
les numéros de sécurité sociale, les numéros de téléphone ou encore des mots de passe et j’en
passe. Il y a en tout 120 types de données reconnus. Cette API fonctionne simplement en lui
envoyant un texte ou un document et elle met en évidences les données sensibles en leur donnant
un contexte.
3.Exemple

L’API cherche parmi 120 critères et essayent de les retrouver dans le texte. A l’issue de cette
recherche celle ci donne un degré de confiance à sa prévision (very likely, likely, passable...)
4.Utilisations possibles
Une utilisation surprenante est à l’instar du FBI le masquage sur des documents scannés :
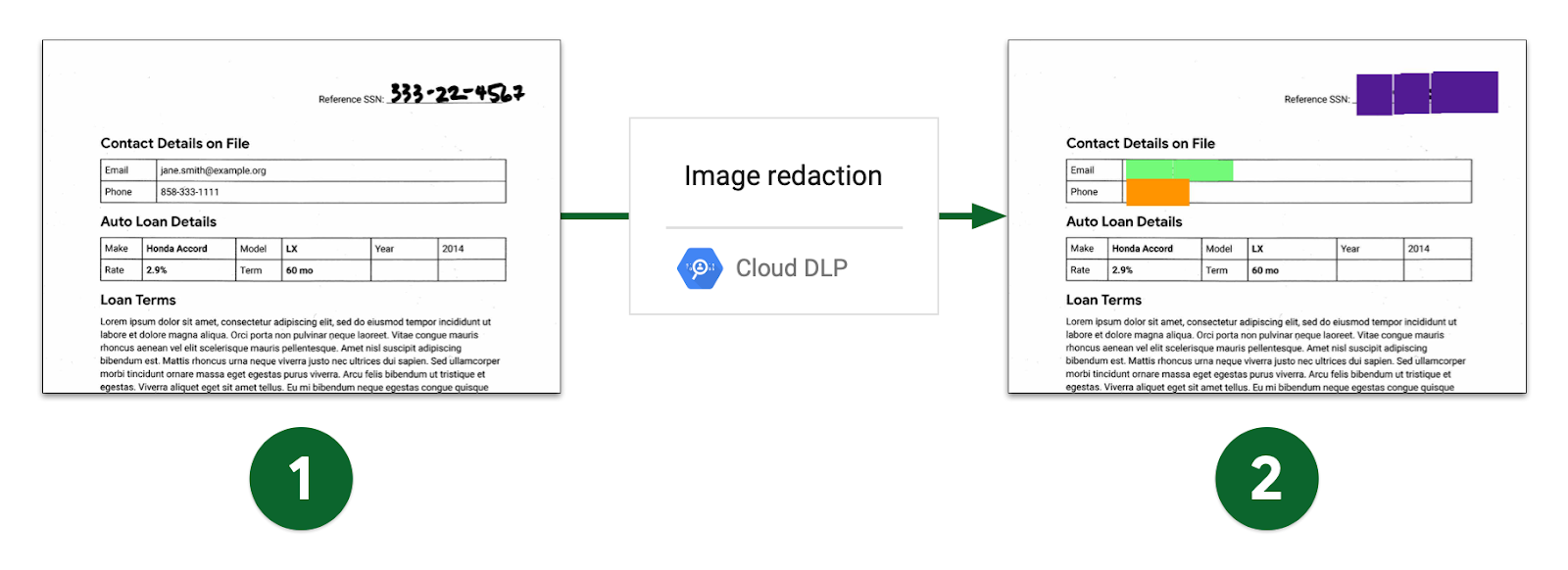

L’API peut aussi masquer dans un texte les données sensibles en remplaçant les caractères par un
caractère générique tel que *,#,%....
My email is ***
Plus intéressant encore l’API peut aussi remplacer une donnée sensible par son type :
My email is [EMAIL_ADDRESS]
Cette fonction ravira les data scientists qui grâce à elle pourront catégoriser des nombres, des
emails, des noms de personne et pourra rendre leurs modèles encore plus performants.
Il est aussi possible de créer ces propres rubriques. Par exemple par défaut aucune rubrique Salaire
n’existe. Il ne tient qu’à vous de la rajouter en utilisant les modèles.
Vous allez trouver un bon nombre d’acteurs spécialisés dans chaque domaine : un acteur qui
détectera les données médicales, un autre pour les données bancaires, un autre pour les rapports
scientifiques, un autre pour les images….
Ils seront tous certainement un peu meilleur que dlp dans leur domaine mais le vrai avantage de
cloud dlp de Google c’est de centraliser toutes ces analyses au sein de la même API.
5.Confidentialité
Pas de miracle dans cette partie. L’outil ne détecte malheureusement pas tout seul ce qui est
confidentiel et il faudra faire vos propres règles. Pour être un peu plus précis ce qui pose problème
dans tous les outils de reconnaissance de confidentialité c’est la notion de confidentialité : elle est
différente pour tout le monde et si vous demandez à quelqu’un ce qui est confidentiel dans la
majorité des cas il va vous dire que tout ce qu’il fait est confidentiel. Il y a tellement de raisons
possibles à cela et cet article ne débattra ni de philosophie ni de psychologie ni de gestion et mode
de motivation du personnel. Savez-vous définir si vous ouvrez un document s’il est confidentiel ou
non et ce pour tous les types de documents de votre entreprise? Voilà à quoi l'algorithme doit
répondre.
6.Tarif
Le tarif est très correct pour ce genre de travail et Google annonce 900€ pour 1 To de données
analysées.
7.Performance
C’est le seul petit bémol que je peux dire sur cette API, lors d’un test d’intégration à BigQuery cette
API ne s’est pas montrée à la hauteur de ce que j’attendais. Plus d’un jour pour traiter 100 000
lignes cela m’a paru un peu exagéré, je pense que cela est dû à l’intégration de l’API dans Bigquery
plus que de l’API elle même. Parce qu’à chaque fois que j’ai utilisé l’API seule je n’ai pas noté de
temps de latence trop grand.
8.Conclusion
Cette API est le véritable couteau suisse du traitement de données sensibles. Elle est simple ne
nécessite pas de licence (coût à l’utilisation), pas de machine (serverless) et aucune maintenance
de votre part. Elle est en outre sans engagement.
Le traitement automatique de données s’intensifiant et comme le GDPR interdit explicitement aux
algorithmes de machine learning de stocker des données personnelles cette API vous permettra de
nettoyer vos données avant et après traitement. Si vous avez vous aussi ce genre de
problématiques n’hésitez plus et tester cette solution.


Commentaires
Enregistrer un commentaire